13 Capstone Project
Over the past few chapters we went over
In this capstone project, we will go over how you can present your expertise as a data engineer to a potential hiring manager.
The main objectives for this capstone project are 1. Understanding how the different components of data engineering work with each other 2. How to model and transform data in the 3-hop architecture 3. Clearly explain what your pipeline is doing, why, and how
Let’s assume we are working on modeling the TPCH data and creating a data mart for the sales team to create customer metrics that they can use to strategize how to cold-call customers.
13.1 Presentation matters
When a hiring manager reviews your project, assume that they will not read the code. Typically, when people look at projects, they browse high-level sections. These includes
- Outcome of your project
- High-level architecture
- Project structure to understand how your code works
- Browse code for clarity and code cleanliness
We will see how you can address these.
13.2 Run the pipeline and visualize the results
Open Airflow UI at http://localhost:8080, login with username/password as airflow and run the dag as shown below.
We use the python Plotly library to create a simple HTML dashboard as shown below.
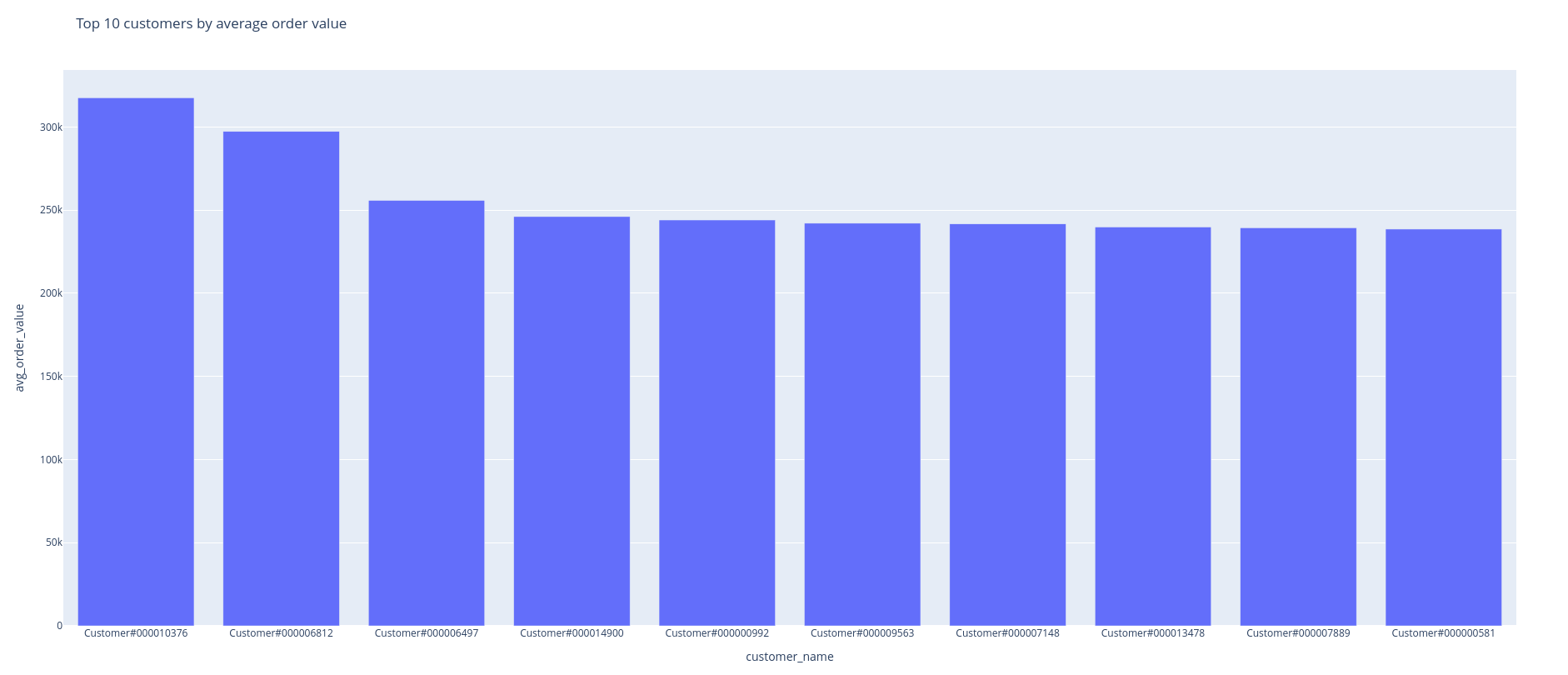
13.3 Start with the outcome
We are creating data to support the sales team’s customer outreach efforts. For this, we need to present customers who are most likely to convert. While this is a complex data science question, a simple approach could be to target customers who have the highest average order value (assuming high/low order values are outliers).
Create a dashboard to show the top 10 customers by average order values as a descending bar chart.
Note The Python script to create the dashboard is available at airflow/tpch_analytics/dashboard.py.
13.4 High-level architecture
The objective of this is to show your expertise in
- Designing data pipelines, by following industry standard 3-hop architecture
- Industry standard tools like dbt, Airflow, and Spark
- Writing clean code using auto formatters and linters
Our base repository comes with all of these set up and installed for you to copy over and use.
13.5 Putting it all together with an exercise
Use this Airflow + dbt + Spark setup to bootstrap your own project, as shown below:
cp -r ./data_engineering_for_beginners_code/airflow ./your-project-name
cd you-project-name
# Update README.md with your specifics
git init
git add .
git commit -m 'First Commit'Create a new GitHub repo at GitHub Create Repo with the same name as your project.
and follow the steps under …or push an existing repository from the command line
13.6 Exercise: Your Capstone Project
Find a dataset that interests you, showcasing an innovative perspective on the data. Outcome should be shown with data.
Read this article to help you identify a problem space and datasets.
Read this article for more information on formattting a project for hiring managers