Python connects the different part of your data pipeline
Python is the glue that holds the various parts of your data pipeline together. While powerful data processing engines (Snowflake, Spark, BigQuery, etc) have made processing large amounts of data efficient, you still need a programming language to tell these engines what to do.
In most companies, Python dominates the data stack. You’ll typically use Python to pull data from the source system (Extract), tell the data processing engine how to process the data (e.g, via SQL queries on Snowflake or SQL/Dataframe query on Spark), and load data into its destination.
In this section, we will cover the basics of Python, its application in data engineering, and conclude with a topic crucial for ensuring code changes don’t break existing logic (testing).
Data is stored on disk and processed in memory
Python is not the most optimal language for large-scale data processing. You would often use Python to tell a data processing engine what to do. For this reason, it’s critical to understand the difference between disk and memory.
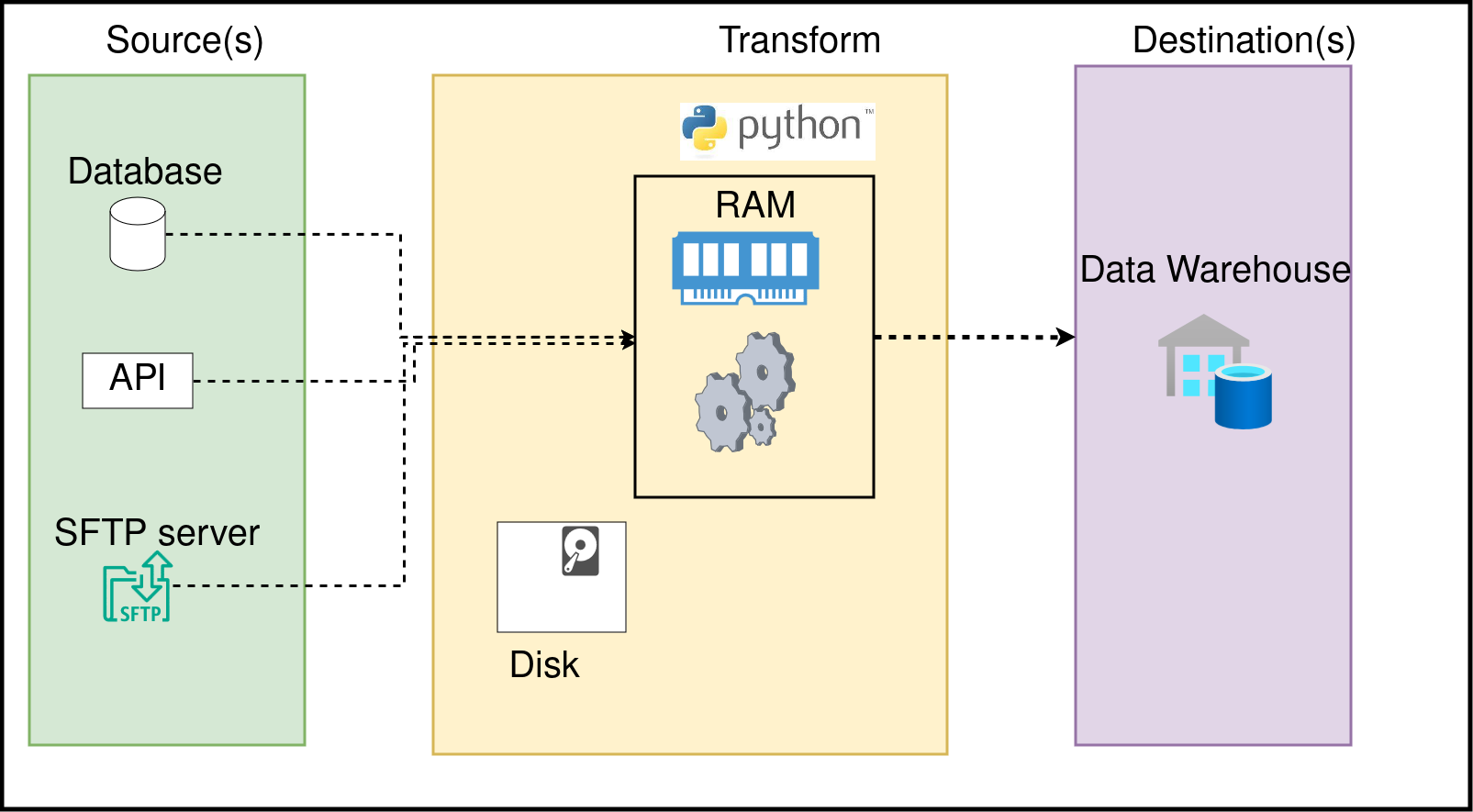
When we run a Python (or any language) script, it is run as a process. Each process will use a part of your computer’s memory (RAM). Understanding the difference between RAM and Disk will enable you to write efficient data pipelines; let’s go over them:
Memoryis the space used by a running process to store any information that it may need for its operation. The computer’s RAM is used for this purpose. This is where any variables you define and the Pandas dataframe you use will be stored.Diskis used to store data. When we process data from disk (read data from a CSV, etc.), it means that our process reads data from disk into memory and then processes it. Computers generally use HDDs or SSDs to store files.
RAM is expensive, while disk (HDD, SSD) is cheaper. One issue with data processing is that the memory available to use is often less than the size of the data to be processed. This is when we utilize distributed systems, such as Spark or DuckDB, which enable us to process data larger than memory.
As we will see in the transformation sections, when we use systems like Spark, Snowflake, or Duckdb, Python is just the interface; the real data processing (and Memory and disk usage) depends on the data processing engine.