9 Most companies use the multi-hop architecture
In the previous chapter, we learnt about the different types of tables in data warehouse modeling: fact, dimension, OBT, and summary tables.
But which table should be built first, and which types of tables are built based on other types of tables?
Note For a pipeline/transformation function/table, inputs to it are called upstream, and outputs from it are called downstream.
This is where standard data flow models provide us with a clear guideline on how to transform our data in layers, enabling easy maintenance of warehouse tables.
Most industry-standard patterns follow a 3-hop (or layered) architecture.
They are
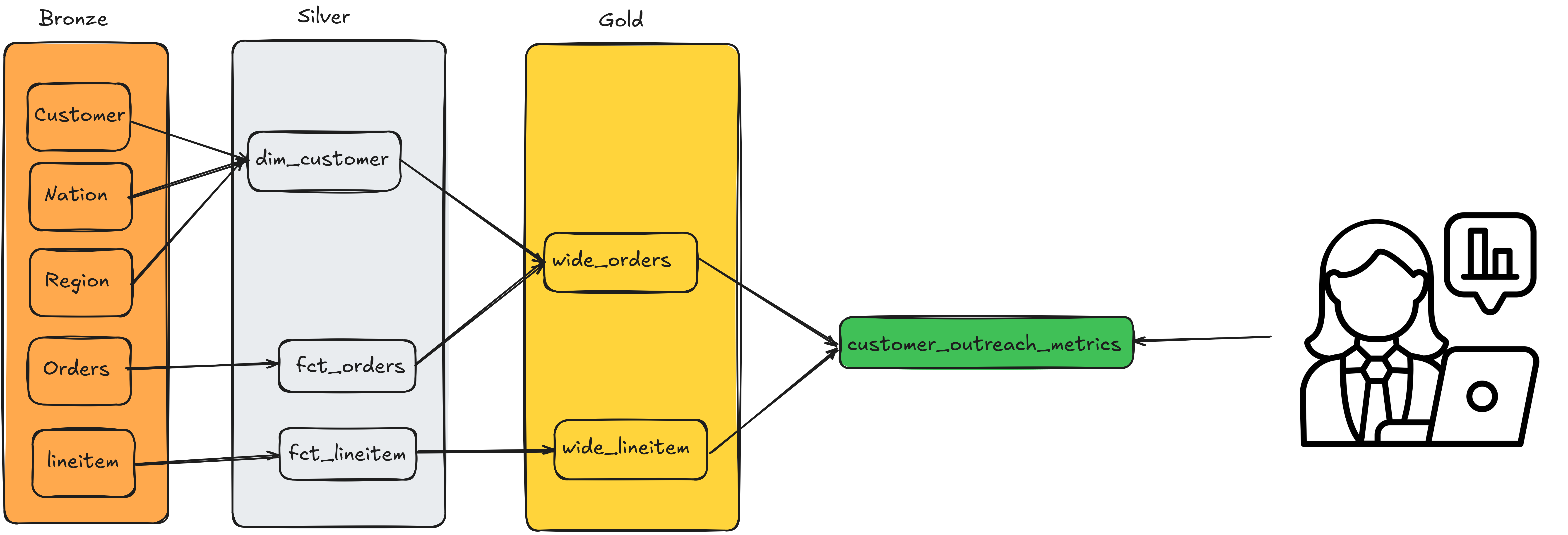
Base/Raw layerstores data from upstream sources as is.Bronze/Stage layerIn this layer, the raw data is lightly cleaned by standardizing on column naming conventions and assigning the right data types to the data.Silver/Intermediate layerIn this layer, data from the bronze/stage is transformed into facts and dimensions.Gold/Marts layerIn this layer, the modelled data is pre-aggregated and summarized as required by the end user. This layer ensures that the same metric definitions are consistently used across business use cases.
Note The boundaries of fact, dimension, and OBT between silver and gold vary by company. Still, the general idea of facts and dimensions flowing into OBT and then into pre-aggregated tables remains consistent.
Most frameworks/tools propose their version of the 3-hop architecture: 1. Apache Spark: Medallion architecture uses the bronze/silver/gold naming. 2. dbt: Project Structure uses the source/stage/core/mart naming.
Shown below is the dbt UI (which we cover in the dbt chapter) on how TPCH data can be modelled based on dbt’s 3-hop architecture:
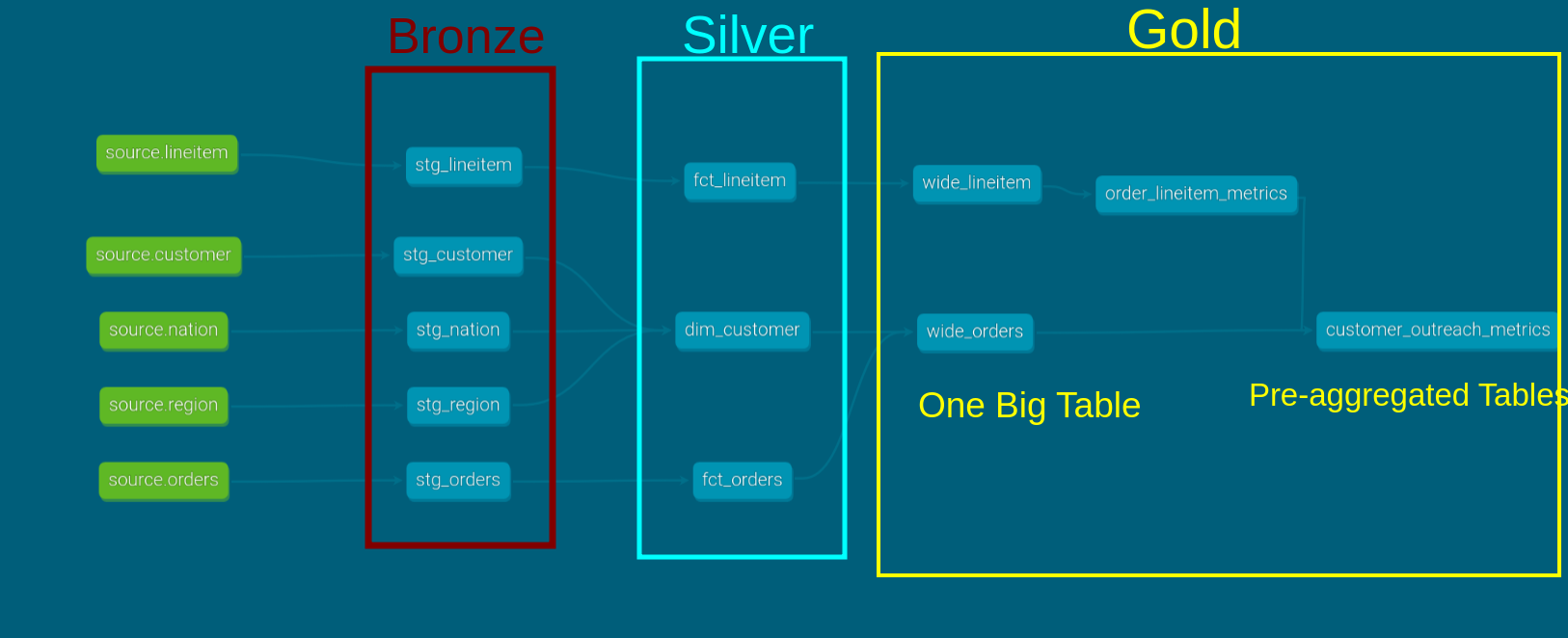
At larger companies, multiple teams work on different layers of the organization. A data ingestion team may bring the data into the bronze layer, and other teams may build their own silver and gold tables as necessary.